| Land | Elev-ID | Skole-ID | Trinn | Kjønn | Forventet utdanning | Likestilling | Sosioøkonomisk status |
|---|---|---|---|---|---|---|---|
| Spania | 51180119 | 5118 | 8 | Gutt | Kort utdanning | 42.63710 | 0.17825 |
| Spania | 51210112 | 5121 | 8 | Gutt | Ungdomsskole | 57.13913 | 1.22299 |
| Spania | 51430108 | 5143 | 8 | Jente | VGS | 49.42491 | 0.57663 |
| Spania | 50880122 | 5088 | 8 | Jente | Høyere utdanning | 65.70400 | -0.85618 |
| Norge | 50020111 | 5002 | 9 | Jente | Kort utdanning | 65.70400 | -0.05390 |
| Norge | 50470622 | 5047 | 9 | Gutt | Høyere utdanning | 52.66245 | -0.53658 |
| Norge | 51260113 | 5126 | 9 | Jente | Høyere utdanning | 65.70400 | -0.92911 |
| Spania | 51320206 | 5132 | 8 | Jente | VGS | 31.55703 | -1.06462 |
| Norge | 50610223 | 5061 | 9 | Gutt | Ungdomsskole | 42.63710 | -0.90046 |
| Spania | 51380217 | 5138 | 8 | Gutt | Høyere utdanning | 52.66245 | -0.47464 |
| Norge | 51030119 | 5103 | 9 | Jente | Ungdomsskole | 65.70400 | 1.17769 |
| Spania | 51240107 | 5124 | 8 | Gutt | VGS | 37.63793 | -1.15001 |
| Spania | 51430101 | 5143 | 8 | Jente | Høyere utdanning | 49.42491 | 0.68916 |
| Spania | 50760123 | 5076 | 8 | Jente | Høyere utdanning | 65.70400 | 0.74741 |
| Spania | 50250621 | 5025 | 8 | Jente | Høyere utdanning | 65.70400 | 0.96238 |
| Norge | 50380222 | 5038 | 9 | Jente | Høyere utdanning | 65.70400 | 0.09765 |
| Norge | 51640210 | 5164 | 9 | Jente | Høyere utdanning | 52.66245 | 0.08229 |
| Spania | 50490515 | 5049 | 8 | Gutt | VGS | 49.42491 | -0.10738 |
| Norge | 51390116 | 5139 | 9 | Gutt | Ungdomsskole | 65.70400 | -0.14096 |
| Spania | 51430128 | 5143 | 8 | Gutt | Ungdomsskole | 37.63793 | -0.09497 |
| Spania | 51540217 | 5154 | 8 | Gutt | Høyere utdanning | 65.70400 | 1.11256 |
| Norge | 51760111 | 5176 | 9 | Gutt | VGS | 52.66245 | -2.27068 |
| Norge | 50240105 | 5024 | 9 | Gutt | Ungdomsskole | 37.63793 | 0.05805 |
| Norge | 51910307 | 5191 | 9 | Gutt | VGS | 42.63710 | -1.87948 |
| Spania | 50100123 | 5010 | 8 | Jente | VGS | 65.70400 | 0.66202 |
| Norge | 51840626 | 5184 | 9 | Jente | Høyere utdanning | 65.70400 | 0.41818 |
| Norge | 51040212 | 5104 | 9 | Annet | Ungdomsskole | 37.63793 | -1.63197 |
| Spania | 50760108 | 5076 | 8 | Gutt | Høyere utdanning | 39.20663 | 0.32023 |
| Norge | 50310416 | 5031 | 9 | Jente | Høyere utdanning | 65.70400 | 1.68152 |
| Norge | 50210215 | 5021 | 9 | Jente | Høyere utdanning | 65.70400 | 0.41443 |
| Norge | 50260108 | 5026 | 9 | Gutt | Høyere utdanning | 65.70400 | 1.00974 |
| Spania | 51390211 | 5139 | 8 | Jente | Høyere utdanning | 65.70400 | 0.56190 |
| Spania | 50130121 | 5013 | 8 | Annet | VGS | 65.70400 | 1.57341 |
| Norge | 51930503 | 5193 | 9 | Jente | VGS | 52.66245 | 0.50591 |
| Spania | 50030103 | 5003 | 8 | Jente | Høyere utdanning | 65.70400 | 0.23861 |
| Norge | 51940228 | 5194 | 9 | Annet | VGS | 49.42491 | 1.09371 |
| Norge | 51500105 | 5150 | 9 | Jente | Høyere utdanning | 65.70400 | 0.07854 |
| Norge | 51230207 | 5123 | 9 | Gutt | Høyere utdanning | 42.63710 | 1.67865 |
| Norge | 51490205 | 5149 | 9 | Gutt | Kort utdanning | 39.20663 | 1.42960 |
| Spania | 51210105 | 5121 | 8 | Gutt | Høyere utdanning | 49.42491 | -0.40563 |
| Norge | 51260108 | 5126 | 9 | Gutt | Kort utdanning | 44.59585 | -1.57158 |
| Norge | 51950416 | 5195 | 9 | Gutt | Høyere utdanning | 65.70400 | 0.67385 |
| Norge | 51000501 | 5100 | 9 | Jente | Høyere utdanning | 65.70400 | 0.47792 |
| Norge | 50430119 | 5043 | 9 | Jente | Høyere utdanning | 49.42491 | 0.07346 |
| Spania | 51010229 | 5101 | 8 | Jente | Høyere utdanning | 40.85939 | -0.43277 |
| Norge | 51000506 | 5100 | 9 | Jente | Høyere utdanning | 65.70400 | -0.47685 |
| Spania | 50340626 | 5034 | 8 | Gutt | Høyere utdanning | 57.13913 | 0.81220 |
| Norge | 51140230 | 5114 | 9 | Gutt | Høyere utdanning | 65.70400 | 0.47792 |
| Norge | 50760521 | 5076 | 9 | Gutt | Høyere utdanning | 65.70400 | 1.14969 |
| Norge | 51400321 | 5140 | 9 | Jente | Høyere utdanning | 49.42491 | 1.31764 |
4 Deskriptiv statistikk
Hver gang du skal analysere et nytt datasett, må du finne måter å beskrive dataene på en kompakt og lett forståelig måte. Dette kalles deskriptiv statistikk, eller beskrivende statistikk. Merk at når man beskriver dataene, så beskriver man kun utvalget, og statistikken som sier noe om populasjonen kommer senere i Kapitel 7.
Det har blitt ganske vanlig å høre begrunnelser som “det er det dataene viser” eller formaninger som “du må se på dataene, dummen!” Jeg tror ikke man kan lære så mye ved å se på dataene, men vi får vel prøve, da, og se hvor mye klokere vi blir. Jeg har forberedt et lite datasett fra den store internasjonale undersøkelsen ICCS, International Civic and Citizenship Education Study. Dette datasettet inneholder variable for kjønn, skole, land, trinn, forventet høyeste fullførte utdanning og en samlevariabel for hvor enig man er i at kjønnene bør ha like rettigheter. Datasettet har 8622 rader, én rad for hver elev, men vi viser bare 50 rader. Se i Tabell 4.1 for å se hva dataene viser.
Nå, ble du noe klokere? Jeg tipper du ikke ble noe klokere, og at du lengter etter å få dataene omarbeidet og presentert på en eller annen måte. Det er det som kalles deskriptiv statistikk.
La oss åpne filen i et statistikkprogram. For å gjøre dette åpner vi filen ICCS.csv og ser hvilke variabler som er lagret i filen, se Figur 4.1.
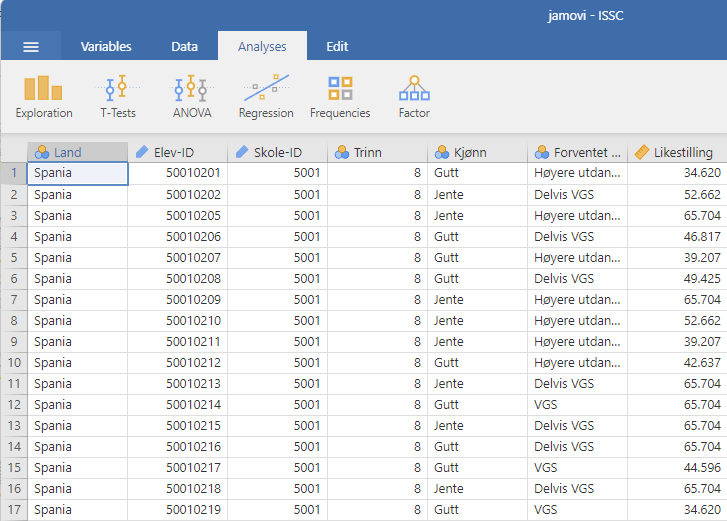
For å få en forståelse av dataene, må vi beregne deskriptiv statistikk (dette kapittelet) og lage noen fine figurer (Kapitel 5). Vi skal først beskrive de nominelle og ordinale dataene. Disse er markert med et symbol med tre prikker, og er altså Land, Trinn, Kjønn og Forventet utdanning.
4.1 Frekvenstabeller og krysstabeller
En av de mest grunnleggende oppgavene innen dataanalyse er telle opp hvor mange du har av de ulike verdiene for nominelle og ordinale variable. Heldigvis er dette enkelt i jamovi.
4.1.1 Frekvenstabeller
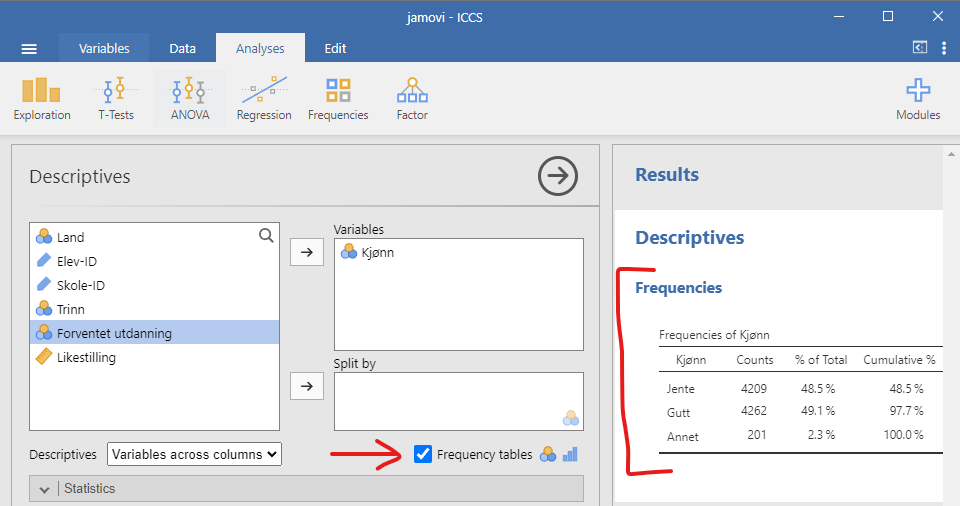
En frekvenstabell viser hvor mange du har av hver verdi for én variabel. I statistikkprogrammet jamovi må man først trykke på Analyses, deretter på “Exploration” og “Descriptives. I menyen som dukker opp er det en avkryssingsboks som heter”Frequency tables”, se Figur 4.2. Vi laster inn Forventet utdanning i “Variables” og krysser av for “Frequency tables”.
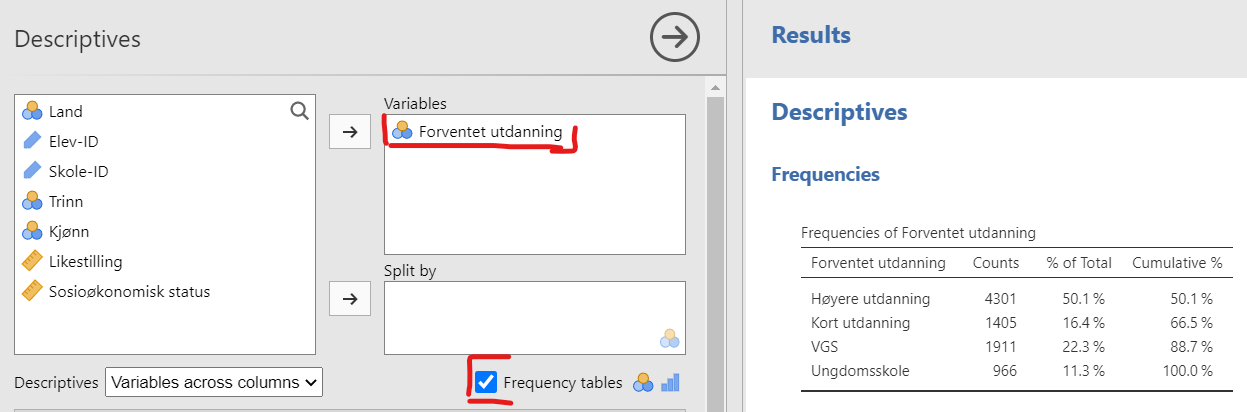
Frekvenstabellen er til høyre i figuren. De viser en opptelling av Forventet utdanning-variabelen. I første kolonne er variabelen øverst, med de ulike verdiene under. I “Counts”-kolonnen finner du hvor mange det var av hver verdi. Kolonnen “% of Total” viser hvor mange prosent dette utgjør. I “Cumulative %” summerer man de foregående prosentene. Slik ser man at 66,5 % av elevene skal ha “Høyere utdanning” eller “Kort utdanning”.
4.1.2 Krysstabeller
I jamovi lager avkrysningsboksen “Frequency tables” kun tabeller for enkeltvariabler. Hvis du ønsker en tabell med to variabler – for eksempel for å kombinere Forventet utdanning og Land for å se om det er forskjell i hvor lang utdanning elevene ser for seg i Norge og Spania -– trenger du en krysstabell (contingency table på engelsk).
Du lager dette i jamovi ved å velge analysen “Frequencies” → “Contingency Tables” → “Independent Samples”. Flytt Forventet utdanning til “Rows”-boksen og Land-variabelen til “Columns”-boksen. Vi gjør et lite ekstra triks og trykker på “Cells” og krysser av for “Percentages: Columns”. Da får du en krysstabell som vist i Figur 4.3.
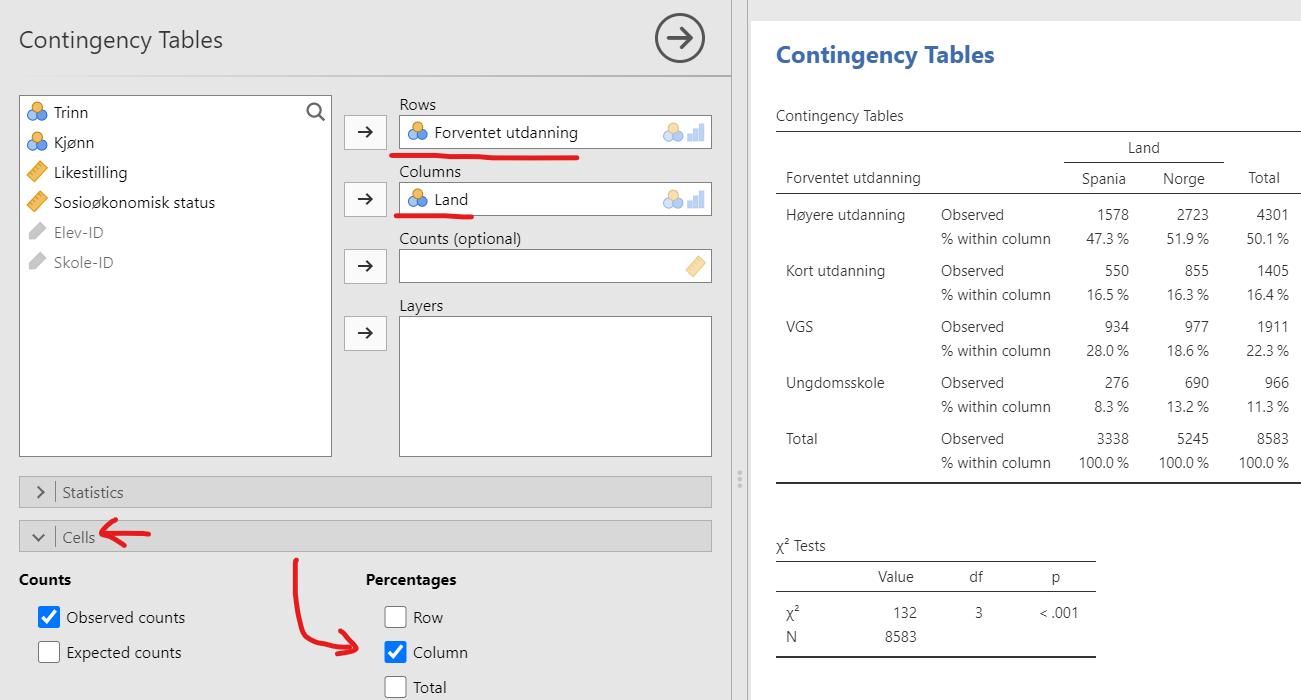
Ikke bekymre deg for “\chi^2 Tests”-tabellen som blir laget. Vi kommer tilbake til dette senere i Kapitel 9.
Når du tolker krysstabellen, husk at “Observed” viser antall observasjoner. For eksempel betyr verdien 550 i første rad at 550 av de spanske elevene i utvalget ser for seg å ta en kort utdanning (for eksempel ett- til to-årig fagskole). I kolonnen “% within columns” står det at dette utgjør 16,5% av et eller annet. Siden vi valgte “% within columns” er det prosentandelen innenfor landet, altså “16,5% av de spanske elevene ser for seg kort utdanning”. Hvis vi hadde valgt “% within rows” hadde det betydd “% av elevene som ser for seg kort utdanning er spanske.”
Krysstabeller er nyttige! Se, langt større andel av de norske elevene ser for seg å avslutte utdanningen etter ungdomsskolen – hvorfor det, mon tro?
4.2 Intermezzo: Variabelen Likestilling
I resten av delkapittelet skal vi fokusere på variabelen Likestilling. Som du kanskje oppfattet fra Kapitel 2 bør man først spørre seg hva variabelen egentlig måler. Dette er viktig nok til at vi bruker litt tid på det.
Jeg fant frem i dokumentasjonen til ICCS 2022 (Fraillon et al., 2024) at Likestilling er en samlevariabel satt sammen av følgende Likert-spørsmål:
- Men and women should have equal opportunities to take part in government.
- Men and women should have the same rights in every way.
- Women should stay out of politics.
- When there are not many jobs available, men should have more right to a job than women.
- Men and women should get equal pay when they are doing the same jobs.
- Men are better qualified to be political leaders than women.
Alle spørsmålene virker jo å måle likestilling på en fin måte, men i Norge virker konstruktet litt tamt. I Norge ville man kanskje spurt om kjønnskvotering til høyere utdanning eller fordeling av foreldrepermisjon, men det hadde sikkert ikke vært så relevant i de andre landene der ICCS avholdes. Og kanskje har ikke ungdomsskoleelever gjort seg opp en mening om foreldrepermisjon, slår det meg!
Å se på rådataene i tabellen på starten av kapittelet, Tabell 4.1, fortalte oss lite Likevel viser jeg et histogram av likestilling-dataene, slik at vi vet hva det er vi prøver å beskrive med deskriptiv statistikk, se Figur 4.4. Neste kapittel inneholder mye mer om histogrammer.
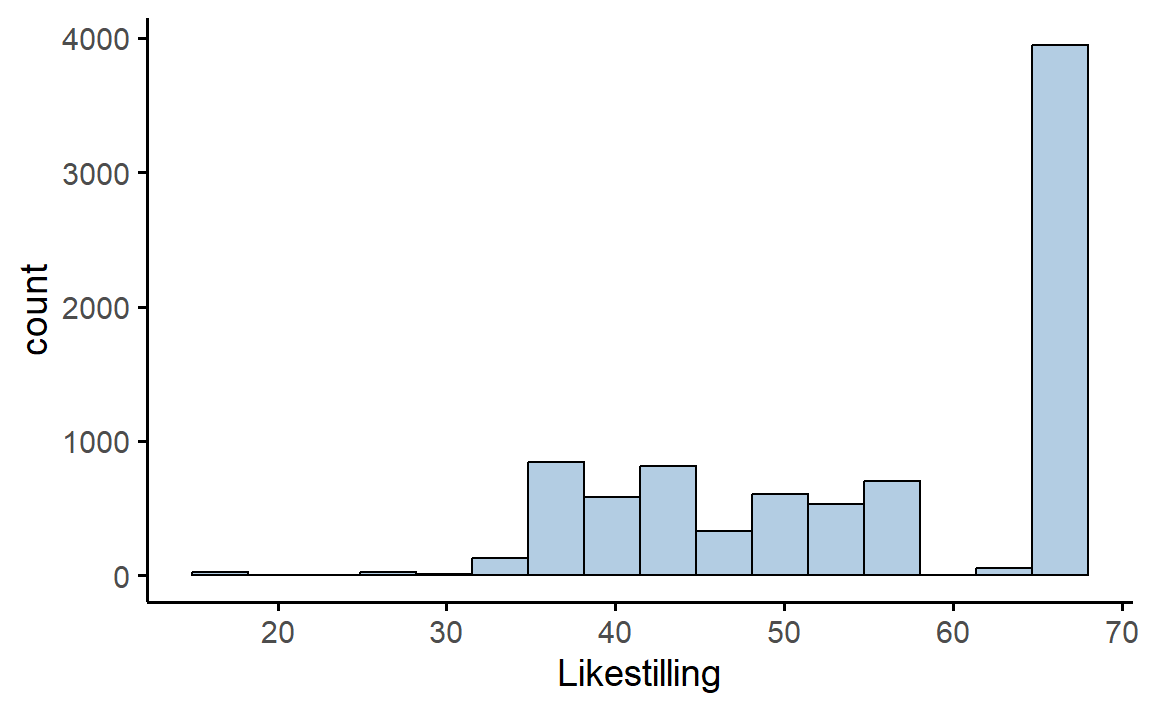
Histogrammet i Figur 4.4 viser oss godt at de fleste svarer veldig høyt på Likestilling, men at en betydelig andel svarer mye lavere. Hvis man ønsker å undersøke videre, for eksempel å undersøke kjønnsforskjeller, så er det bare å lage et histogram for hvert kjønn, Figur 4.5.
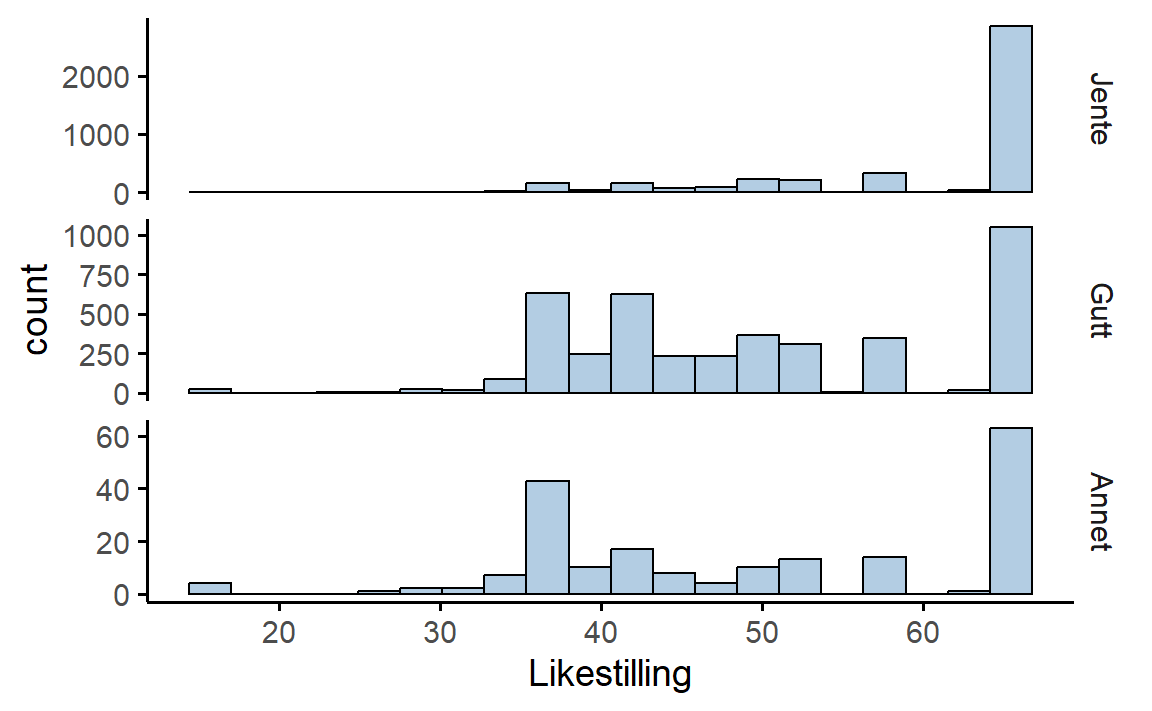
De fleste jentene er skårer maksimumsverdien på Likestilling, mens det blant guttene er vanlig å svare lavere også. Det var ganske få elever som oppga “Annet” på variabelen Kjønn, så det nederste histogrammet er basert på svært få verdier, men ellers likner histogrammet på gutta sitt.
4.3 Sentraltendensmål
Å tegne bilder av dataene, som jeg gjorde i Figur 4.4, er en flott måte å vise fram hovedbudskapet i dataene dine, men det kan også være nyttig å sammenfatte dataene med noen få enkle tall. Det første du som regel vil vite noe om, er sentraltendensen, altså hva som er “midten”, “gjennomsnittet”, “det typiske” av dataene. Det finnes mange mål på sentraltendens, men de tre mest brukte gjennomsnitt, median og typetall. Vi presenterer hver og en av dem og diskuterer deretter når de er lure å bruke.
4.3.1 Gjennomsnittet
Gjennomsnittet er det vanlige gjennomsnittet du kjenner fra før. Du legger sammen alle verdiene og deler på antall verdier. De første fem verdiene på Likestilling i Tabell 4.1 var
42.6, 57.1, 49.4, 65.7, 65.7,
så gjennomsnittet blir:
\frac{42.6 + 62.9 + 52.7 + 37.6 + 42.6}{5} = \frac{238.4}{5} = 47.68
Dette er selvsagt ikke noe nytt for deg, siden du allerede er godt kjent med gjennomsnitt.
Det som kanskje er nytt for deg er hvordan man kan få statistikk-programvare til å gjøre regnejobben for oss! Når du har mange observasjoner, vi hadde 8622, er det mye lettere å regne ut ting digitalt.
Slik gjør man det i jamovi:
- Klikk på “Exploration”-knappen
- Velg “Descriptives”
- Merk variabelen Likestilling
- Klikk på høyre pil for å flytte den til ‘Variables’-boksen
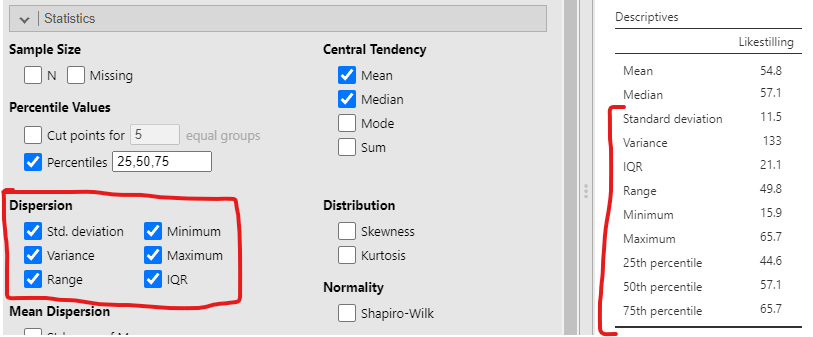
Straks du har gjort dette dukker en tabell med standard deskriptiv statistikk opp på høyre side av skjermen, som vist i Figur 4.6. (Hvis du ikke finner ‘Exploration’-knappen må du trykke på “Analyses” først.)
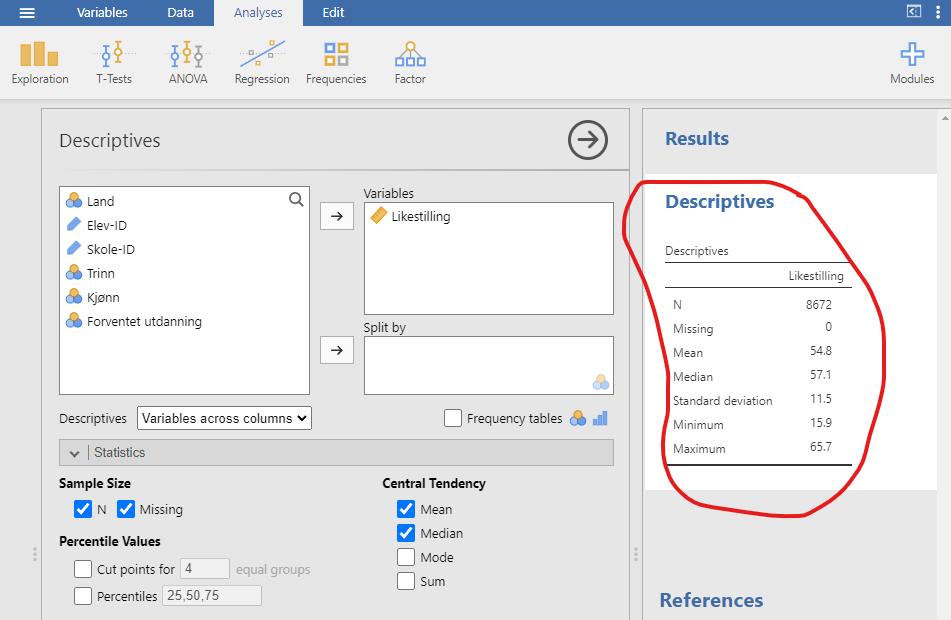
Som du kan se i den røde markeringen i Figur 4.6, viser resultatet at gjennomsnittsverdien for Likestilling er 54,8. I tillegg får du annen nyttig informasjon som det totale antallet observasjoner (N = 8622) 1, antall manglende verdier, samt median-, minimum- og maksimumsverdier og standardavviket for variabelen. (“Manglende verdier” er typisk at elever har unnlatt å svare på et spørsmål, eller at svaret var uleselig. Ingen verdier mangler i dette tilfellet, siden jeg fjernet manglende verdier da jeg forberedte dataene.)
Hva hvis vi skal regne ut gjennomsnittet av variabelen Forventet utdanning? De fem første verdiene av denne variabelen er
Kort utdanning, Ungdomsskole, VGS, Høyere utdanning, Kort utdanning.
Hvordan skal man regne gjennomsnittet av dette? Det går ikke an, for man kan ikke legge sammen verdiene. Derfor kan man bare regne gjennomsnitt for variable med tall, altså variable på intervall- og forholdstallskala.
4.3.2 Medianen
Et annet mål for sentraltendens er medianen, og den er enda enklere å forstå enn gjennomsnittet. Medianen av et sett observasjoner er ganske enkelt middelverdien. Hvis vi tar de fem første verdiene av Likestilling fra Tabell 4.1 igjen, får vi
42.6, 57.1, 49.4, 65.7, 65.7.
For å finne medianen sorterer vi disse tallene i stigende rekkefølge:
42.6, 49.4, 57.1, 65.7, 65.7.
Da ser vi at 57.1 står i midten, så 57.1 er medianen.
Av og til er det ingen verdier i midten, for eksempel her:
1, 3, 5, 6, 10, 15
Her er både 5 og 6 like nære midten. Da er medianen definert til å være gjennomsnittet av disse to verdiene, altså 5,5.
Man kan regne medianen av ordinale data. De fem første verdiene av variabelen Forventet utdanning var
Kort utdanning, Ungdomsskole, VGS, Høyere utdanning, Kort utdanning.
Hvis man sorterer dem i rekkefølge får man:
Ungdomsskole, VGS, Kort utdanning, Kort utdanning, Høyere utdanning.
Da ser man at medianen er Kort utdanning.
Selvfølgelig er det uaktuelt å regne medianen for hånd med våre 8622 verdier. Derfor bruker vi jamovi, som allerede har beregnet en medianverdi på 57.1 for Likestilling, se i den røde markeringen i Figur 4.6.
4.3.3 Gjennomsnitt eller median? Hva er forskjellen?
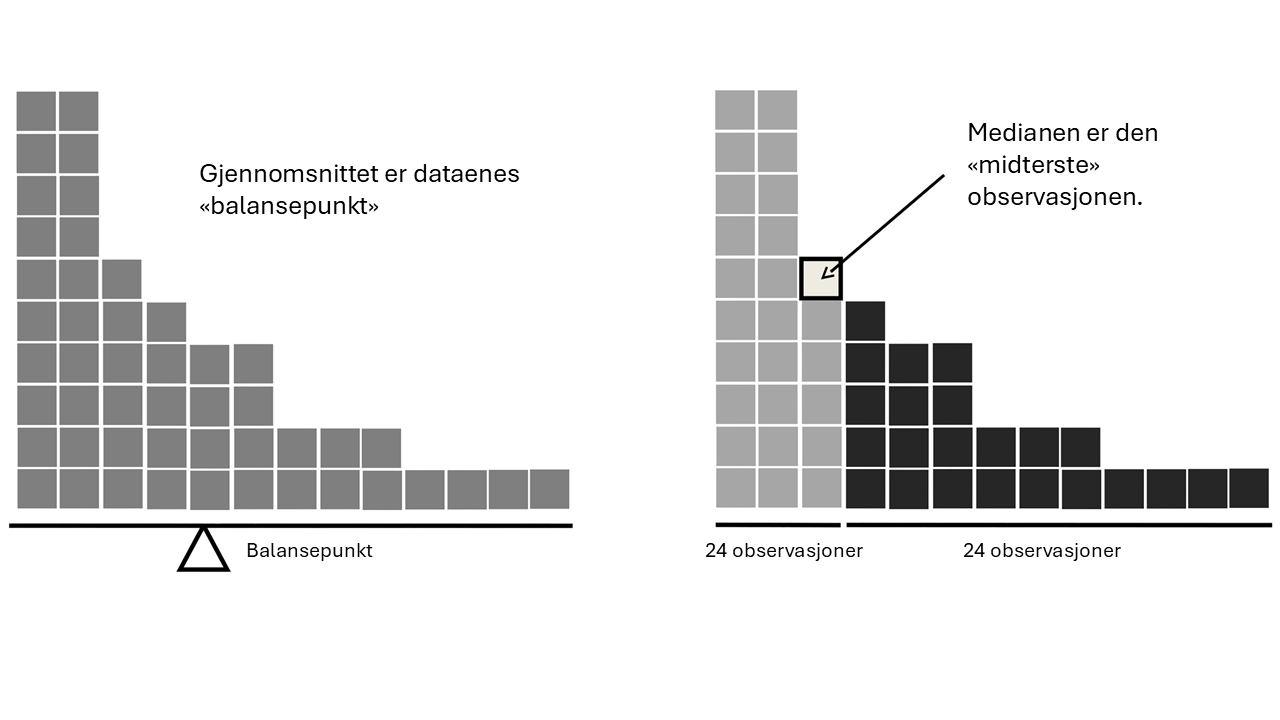
Det er ikke nok å vite hvordan man regner ut gjennomsnitt og medianer – du må også forstå hva de forteller deg om dataene dine. Dette er illustrert i Figur 4.7. Tenk på gjennomsnittet som “tyngdepunktet” til datasettet ditt, mens medianen er “middelverdien” i dataene. Valget mellom dem avhenger av hvilken type data du har og hva du ønsker å oppnå. Her er noen praktiske retningslinjer:
For nominale data kan du hverken bruke gjennomsnitt eller median.
For ordinale data vil medianen stort sett være det beste valget. Medianen bruker kun rekkefølgeinformasjonen i dataene dine (hvilke tall som er større) og trenger ikke eksakte tallverdier. Dette passer perfekt for ordinale data. Gjennomsnittet derimot, er avhengig av de presise tallverdiene. Det er likevel ganske vanlig å regne gjennomsnitt av variable på ordinalnivå. Da setter man, for eksempel, det laveste nivået til tallet 1, det neste nivået til tallet 2, osv.
For intervall- og forholdstallsdata er både median og gjennomsnitt fine valg! Hva du velger avhenger av hva du ønsker å fremheve. Gjennomsnittet har den fordelen at det bruker all verdiene i dataene, men dette gjør den svært følsom for ekstreme verdier.
Vi må forklare dette ved et eksempel. Tenk deg at Arne (månedsinntekt 50 000 kr), Berit (60 000 kr) og Cato (inntekt 65 000 kr) sitter ved et bord. Gjennomsnittsinntekten ved bordet er 58 333 kr og medianinntekten er 60 000kr. Begge disse er gode sentralverdier for dataene.
Så kommer Erling Braut Haaland og setter seg ved bordet (månedsinntekt 30 000 000 kr). Plutselig gjør gjennomsnittsinntekten et byks til 7.54375^{6}, mens medianen kun stiger til 6.25^{4}! Gjennomsnittsverdien representerer plutselig ikke de andre i det hele tatt, fordi den ekstreme verdien til Erling Braut Haaland trekker gjennomsnittet opp for mye. Medianen, derimot, ser ikke den ekstreme verdien i det hele tatt.
Hvis du er interessert i den totale inntekten ved bordet, kan gjennomsnittet være relevant. Men hvis du vil vite hva som er en typisk inntekt ved bordet, ville medianen gi deg et mye mer representativt bilde.
Dette illustreres også i Figur 4.7, hvor du kan se at når histogrammet er asymmetrisk, ligger medianen nærmere “hovedvekten” av dataene, mens gjennomsnittet blir trukket mot “halen” der de ekstreme verdiene befinner seg.
Valget mellom gjennomsnitt og median er viktig når dataene har en hale som trekker opp eller ned gjennomsnittet. Et eksempel er at USA har høyere gjennomsnittsinntekt enn Norge, men lavere medianinntekt. Årsaken er at USA har flere superrikinger som trekker opp gjennomsnittet på samme måte som Erling Braut Haaland gjorde i eksempelet. Men den vanlige lønnstager sin inntekt er nok mer lik medianinntekten, og den er høyere i Norge.
4.3.4 Typetallet
Typetallet til en variabel er den verdien som forekommer hyppigst. Vi kan finne typetallet til nominelle variable, noe som gjør dem velegnet til slike data. En nominell variabel i ICCS-dataene er Kjønn. Typetallet til Kjønn vil si oss hvilket kjønn det er flest av i dataene. De fem første verdiene er:
Gutt, Gutt, Jente, Jente, Jente.
Typetallet er Jente fordi det var flest av den verdien.
Hvis vi skal finne typetallet for Kjønn i hele datasettet må vi sette oss ned og telle hvor mange det er av Gutt, Jente og Annet. Selvsagt gjør vi det heller med programvare, altså jamovi. Figur 4.8 viser et skjermbilde av hvordan det ser ut.
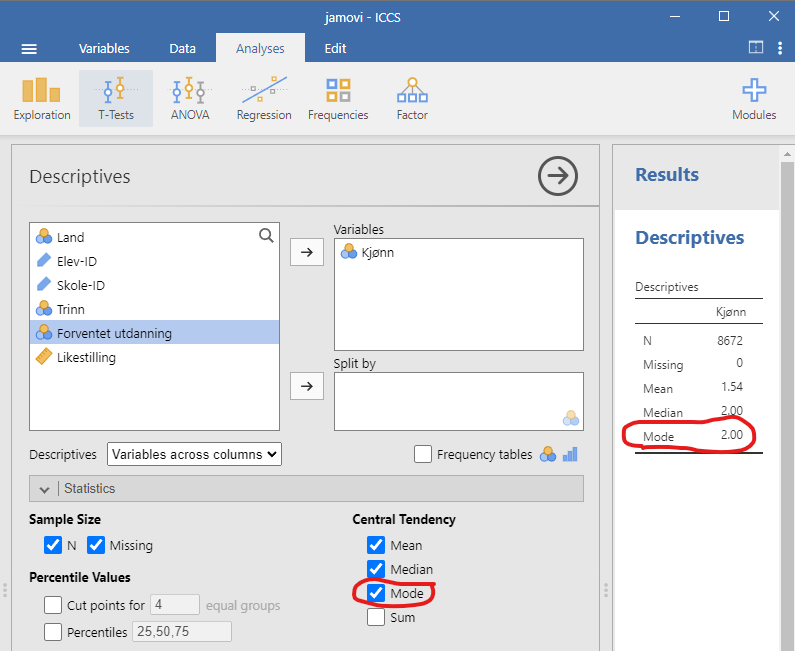
I Figur 4.8 har jeg valgt variabelen “Kjønn” ved å dra den over i vinduet “Variables”. Det engelske ordet for typetall er “mode”, og derfor trykket jeg på “Mode”. Resultatet er skuffende, for jamovi velger å si at typetallet er 2. (Se i den rød håndtegnede ellipsen.) Hæ? Typetallet må jo være “Gutt”, “Jente” eller “Annet”! Dette er en beklagelig teknikalitet som er forårsaket av at nominelle variable sine verdier er lagret som heltall (noe de ikke er), men tolkes som kategorier (noe de er). Du kan se at jamovi tilogmed har regnet ut Kjønn sitt gjennomsnitt og funnet ut at det er 1,54. 💩
For å finne ut av hva typetallet 2 betyr, må du trykke på ‘Variables’ → ‘Kjønn’ → ‘Edit’, se Figur 4.9. Du kan se at “Jente” er lagret som 1, “Gutt” som 2 og “Annet” som 3. Typetallet 2 er altså “Gutt”, så det er flest gutter i datasettet.

En mer tilfredsstillende måte å finne typetallet på er å telle opp antallet av alle verdiene. Dette kalles å lage en frekvenstabell. I jamovi kan man akkurat som før trykke på “Analyses” → “Exploration” → “Descriptives”, men nå kan man velge “Frequency table”, se Figur 4.10.
Selv om typetallet oftest beregnes for nominelle variable, kan det være nyttig å vite typetallet til en ordinal-, intervall- eller forholdstallsvariabel. For eksempel, hvis vi tenker oss tilbake til variabelen Likestilling og histogrammet i Figur 4.4, så husker vi at den største søyla var ved den høyeste verdien. Det betyr at typetallet er den høyeste verdien – noe som er litt betryggende.
4.4 Spredningsmål
Alt vi har sett på så langt handler om sentraltendens, altså hvilke verdier som ligger “i midten” eller som er mest “typiske” i dataene våre. I tillegg trenger vi ofte å å forstå hvor spredt dataene er. Ligger de fleste observasjonene tett rundt gjennomsnittet, eller er de spredt jevnt utover? Dette kaller vi spredning.
La oss utforske fire ulike måter å måle spredning på ved hjelp av ICCS-dataene. Hvert spredningsmål har sine egne fordeler og ulemper, så det er nyttig å kjenne til flere.
4.4.1 Variasjonsbredde
Variasjonsbredden er det aller enkleste spredningsmålet. Den regnes ut ved å ta den største verdien minus den minste verdien. I Figur 4.11
Variasjonsbredden er lett å forstå, men har en egenskap som ofte er en ulempe: den påvirkes veldig av ekstreme verdier.
Se for deg denne lille datamengden: -100, 2, 3, 4, 5, 6, 7, 8, 9, 10
Her får vi en variasjonsbredde på hele 110 på grunn av den ene ekstreme verdien (-100). Men hvis vi fjerner denne ekstreme verdien, blir variasjonsbredden bare 8. Det er en enorm forskjell! Dette må man være obs på når man benytter variasjonsbredden.
4.4.2 Kvartilbredde
Kvartilbredden er litt som variasjonsbredden, men i stedet for å regne ut forskjellen mellom den største og minste verdien, regner vi ut forskjellen mellom tjuefemte persentil og syttifemte persentil. Ordet “kvartil” henspiller på “kvart” og “persentil”, og som vi skal se må man regne ut hvor hver kvart av dataene ligger.
Hvis du kjenner begrepet persentil fra før, kan du tenke på det slik: den 10. persentilen til en variabel er det minste tallet x slik at 10% av verdiene ligger under denne verdien. Dette er faktisk ikke helt nytt -– medianen er nemlig den femtiende persentilen siden femte prosent av verdiene ligger under denne verdien! I jamovi finner du enkelt hvilken som helst persentil ved å huke av for “Percentiles” under ‘Exploration’ → ‘Descriptives’ → ‘Percentile Values’.
Som du kan se tilbake i Figur 4.11, tilsvarer kvartilbredden (interquartile range, IQR) for variabelen Likestilling differansen mellom 25. og 75. persentil, altså 65.7 - 44.6 = 21.1. Siden 25% av dataene er mindre enn 44.6 og 75% av dataene er mindre enn 65.7, ligger 50% av dataene i et intervall som er 21.1 bredt. Legg også merke til at 50. persentil og medianen har samme verdi, 57.1, akkurat slik det skal være. I forskningsartikler oppsummeres alt dette slik:
The median value of gender equality was 57.1 (IQR = 44.6 – 65.7).”
Dette er en effektiv måte å vise sentraltendens og spredning. Medianen viser hva midtpunktet i dataene er og kvartilbredden viser hvor spredt halvparten av verdiene ligger rundt medianen. Merk at kvartilbredden ikke fungerer like godt for å vise spredningen rundt et gjennomsnitt. Årsaken er at gjennomsnittet kan ligge utenfor 25. og 75. persentil. (Bare tenk på kvartilbredden og gjennomsnittslønna når Haaland satte seg ved bordet i eksempelet i Seksjon 4.3.3.)
Variasjonsbredden var veldig påvirket av ekstreme verdier, men kvartilbredden er ikke det – den ignorerer de 25% av dataene som har størst verdi og de 25% av dataene som har minst verdi.
4.4.3 Varians
De to spredningsmålene vi har sett på så langt er differanser, enten mellom største og minste verdi eller mellom tjuefemte og syttifemte persentil. En annen tilnærming er å regne ut hvor stort et “typisk” avvik er fra sentraltendensen.
Vi tar et eksempel. De fem første verdiene på variabelen Likestilling er vist i første kolonne i Tabell 4.2. Gjennomsnittet av Likestilling er 54,8. Da kan man regne ut hvor mye hver verdi avviker fra gjennomsnittet. I tabellen ser vi at første verdi avviker 12.2 fra gjennomsnittet. 2 Den nye kolonnen Avvik fra gjennomsnittet inneholder alle disse avvikene. Disse verdiene kan man bruke til å beskrive spredningen, for eksempel ved å regne gjennomsnittet eller medianen av dem. Slike spredningsmål blir brukt, men de desidert vanligste spredningsmålene legger til et steg til.
| Likestilling | Avvik fra gjennomsnittet |
|---|---|
| 42.6 | 12.2 |
| 57.1 | 2.3 |
| 49.4 | 5.4 |
| 65.7 | 10.9 |
| 65.7 | 10.9 |
Det første av de vanligste og mest elegante spredningsmålene vi skal møte er varians. For å regne ut dette tar man ikke gjennomsnittlig avvik, men gjennomsnittlig kvadratisk avvik. Det første avviket var 12{,}2 og da er det kvadratiske avviket 12{,}2^2 = 148{,}84, man opphøyer altså tallet i andre. Da kan man regne ut kvadratet av alle avvikene, se Tabell 4.3.
| Likestilling | Avvik fra gjennomsnittet | Kvadratisk avvik |
|---|---|---|
| 42.6 | 12.2 | 148.84 |
| 57.1 | 2.3 | 5.29 |
| 49.4 | 5.4 | 29.16 |
| 65.7 | 10.9 | 118.81 |
| 65.7 | 10.9 | 118.81 |
Variansen er definert som gjennomsnittet av alle disse kvadratiske avvikene. Fra jamovi sine utregninger ser vi at variansen til Likestilling var 133. Hvis du husker histogrammet i Figur 4.4, så stusser du sikkert litt nå, for verdiene på Likestilling strakk seg fra ca. 15 til ca. 70. Hvordan kan det da gi mening at variansen er 133? Svaret er at det ikke gir mening og at variansen er vanskelig å tolke.
Grunnen til at variansen er vanskelig å tolke er fordi vi kvadrerer alle verdiene. Hvis vi sier Likestilling blir målt i “likestillingspoeng”, så blir et avvik på 12,2 likestillingspoeng til et kvadratisk avvik på 148,84 “kvadratlikestillingspoeng”. Det er en enhet jeg ikke klarer å se for meg. For å vise hvor absurd det er: se for deg at gjennomfører en 12 minutters løpstest i kroppsøving – Cooper-testen – for alle elevene på skolen og regner du ut at gjennomsnittlig løpslengde er 2300 meter og at variansen er 16000 kvadratmeter. For meg er ikke et areal et meningsfullt mål for spredningen av elevenes løpsdistanser! Grunnen til at varians likevel er et viktig spredningsmål er fordi har så mange gode matematiske egenskaper, men de skal vi ikke gå inn på videre, men de gjør at varians er motoren i nesten all statistikk.
Note
Hvis du er nysgjerrig på variansen sine matematiske kvaliteter: Den kanskje viktigste egenskapen er at varianser er additive. Det betyr at hvis du har to variabler X og Y med varianser Var(X) og Var(Y) og du lager en ny variabel Z = X + Y, så blir variansen til Z ganske enkelt Var(X) + Var(Y). Dette ligger bak utsagn som “foreldrenes utdanningsbakgrunn forklarer 30% av elevenes skoleresultater”.
Så hvordan tolker du variansen? Deskriptiv statistikk skal tross alt beskrive ting og variansen virker bare som et meningsløst tall som er helt ubrukelig hvis du vil kommunisere med et faktisk menneske. Løsningen er standardavviket.
4.4.4 Standardavvik
Du kan stole på oss om at varians er flott på grunn av alle de praktiske matematiske egenskapene, som vi ikke har gått gjennom her, men du ønsker også et spredningsmål som har de samme enhetene som selve dataene (altså likestillingspoeng, ikke kvadratlikestillingspoeng). Hva gjør du da?
Løsningen er enkel, du tar bare kvadratroten av variansen, noe som kalles standardavviket! Standardavviket løser problemet vårt på en elegant måte. Mens de fleste av oss har liten anelse om hva “spredningen i elevenes løpstest var 16000 kvadratmeter” betyr, så er det mer opplagt hva “spredningen i elevenes løpstest var 400 meter”. Dette er forskjellen på varians og standardavvik. Standardavviket er mye mer intuitivt å forstå siden det er uttrykt i de samme enhetene som de opprinnelige dataene.
Tolkning av standardavvik er likevel litt komplisert. Fordi standardavviket er utledet fra variansen, og variansen er en størrelse som er vanskelig å tolke, så er ikke standardavviket helt enkelt å tolke heller. Derfor husker de fleste kun en enkel tommelfingerregel. Ofte vil 68% av dataene falle innenfor 1 standardavvik fra gjennomsnittet, 95% av dataene falle innenfor 2 standardavvik fra gjennomsnittet, og 99,7% av dataene falle innenfor 3 standardavvik fra gjennomsnittet. Denne regelen er ikke eksakt, men passer veldig godt hvis histogrammet er symmetrisk og “klokkeformet”, slik som i Figur 4.12 (a). Denne figuren inneholder oppkonstruerte data for variabelen Likestilling og viser ikke de ekte dataene fra ICCS-studien. Denne variabelen har samme gjennomsnitt (54,8) og standardavvik (11,5) som ICCS-variabelen, men er normalfordelt. Her stemmer tommelfingerregelen veldig godt.
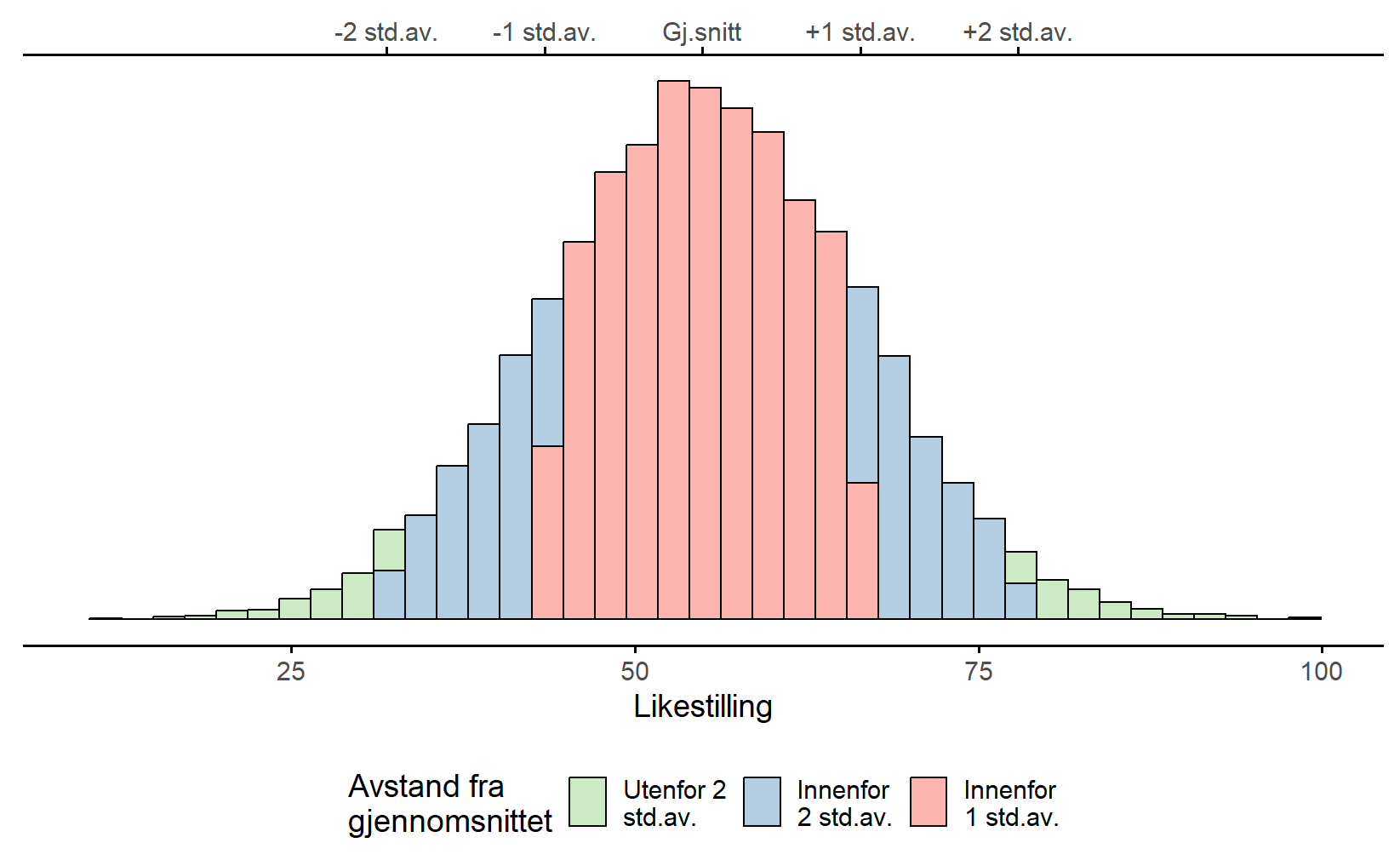
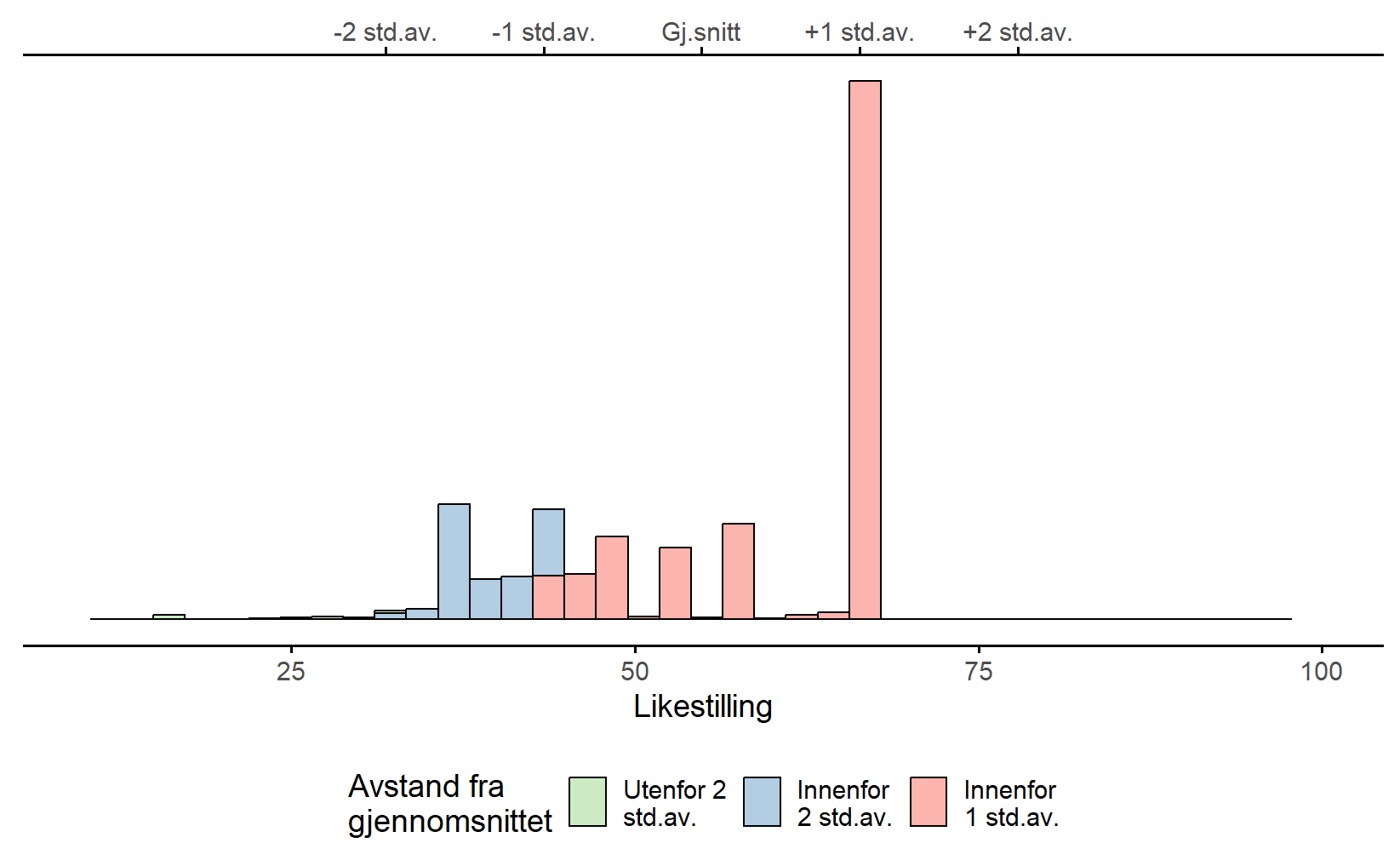
I Figur 4.12 (b) har vi samme diagram, bare for de ekte dataene. Slik vi husker fra starten av kapittelet var variabelen Likestilling overhodet ikke normalfordelt – de aller fleste elevene fikk høyeste skår. Her fungerer tommelfingerregelen ikke, faktisk var 75% av dataene innenfor ett standardavvik av gjennomsnittet (rødt) og 99% av dataene innenfor to standardavvik av gjennomsnittet. La dette være en advarsel mot å kun basere seg på en sentraltendens og spredningsmål for å beskrive dataene: de to histogrammene i Figur 4.12 har samme gjennomsnitt og standardavvik og likevel er dataene helt ulike. Hvis målet med deskriptiv statistikk er å beskrive dataene, noe det jo er, så virker diagrammer å være bedre enn disse tallene.
Når man rapporterer standardavviket til dataene dine i en forskningsartikkel gjøres det gjerne slik:
The mean of the variable Gender equality was 54.9 (SD = 11.5).
Her står SD for standard deviation, som er engelsk for standardavvik.
4.4.5 Hvilket mål skal du bruke?
Vi har gitt deg fire ulike spredningsmål: variasjonsbredde, kvartilbredde, varians og standardavvik. Vi oppsummerer egenskapene deres fort
Variasjonsbredde: Viser avstanden mellom den største og minste verdien i dataene. Variasjonsbredden påvirkes lett av ekstremverdier, så den brukes vanligvis kun når du har spesielle grunner til å fokusere på ytterpunktene.
Kvartilbredde: Beskriver hvor “den midterste halvdelen” av dataene befinner seg. Den er robust mot ekstremverdier og passer perfekt sammen med medianen. Et godt valg!
Varians: Måler det “gjennomsnittlig kvadrerte avviket fra gjennomsnittet”. Variansen er viktig fordi den er så gode matematiske egenskaper som gjør den nyttig i senere kapitler, men den er vanskelig å tolke siden den ikke bruker samme enheter som de opprinnelige dataene. Du vil sjelden se variansen rapportert, men den er grunnlaget for mange statistiske metoder.
Standardavvik: Er kvadratroten av variansen. Den kombinerer matematisk nytteverdi og praktisk tolkbarhet siden den bruker samme enheter som dataene. Den klare favoritten når gjennomsnittet er ditt foretrukne sentralmål. Standardavviket er definitivt det mest brukte variasjonsmålet!
Kort fortalt: kvartilbredde og standardavvik er de to klart mest populære valgene for å beskrive variabilitet, men variansen er den nyttigste i senere utregninger. Variasjonsbredden bruker mange studenter som spredningsmål i mastergradene sine, sikkert fordi den er så intuitiv, så det er viktig å vite om dens styrker og svakheter også.
4.5 Skjevhet
Det er et mål til som er verdt å ta med seg fra dette kapittelet, og det er skjevhet. Vi skal ikke lære å regne ut noen mål på skjevhet, men vi skal lære hva det vil si og hvordan histogrammet til en skjevfordelt variabel vil se ut.
Skjevhet er et mål på asymmetri. En variabel er symmetrisk hvis høyre og venstre side er speilbilder av hverandre, og asymmetrisk hvis de ikke er speilbilder av hverandre. Vi sier at variabelen er venstreskjev hvis verdiene som ligger til venstre for gjennomsnittet ligger langt unna, altså at vi har lengre hale til venstre enn til høyre. Dette kalles også negativ skjevhet. Høyreskjevhet kalles positiv skjevhet. Figur 4.13 er bildet du bør ha i hodet.
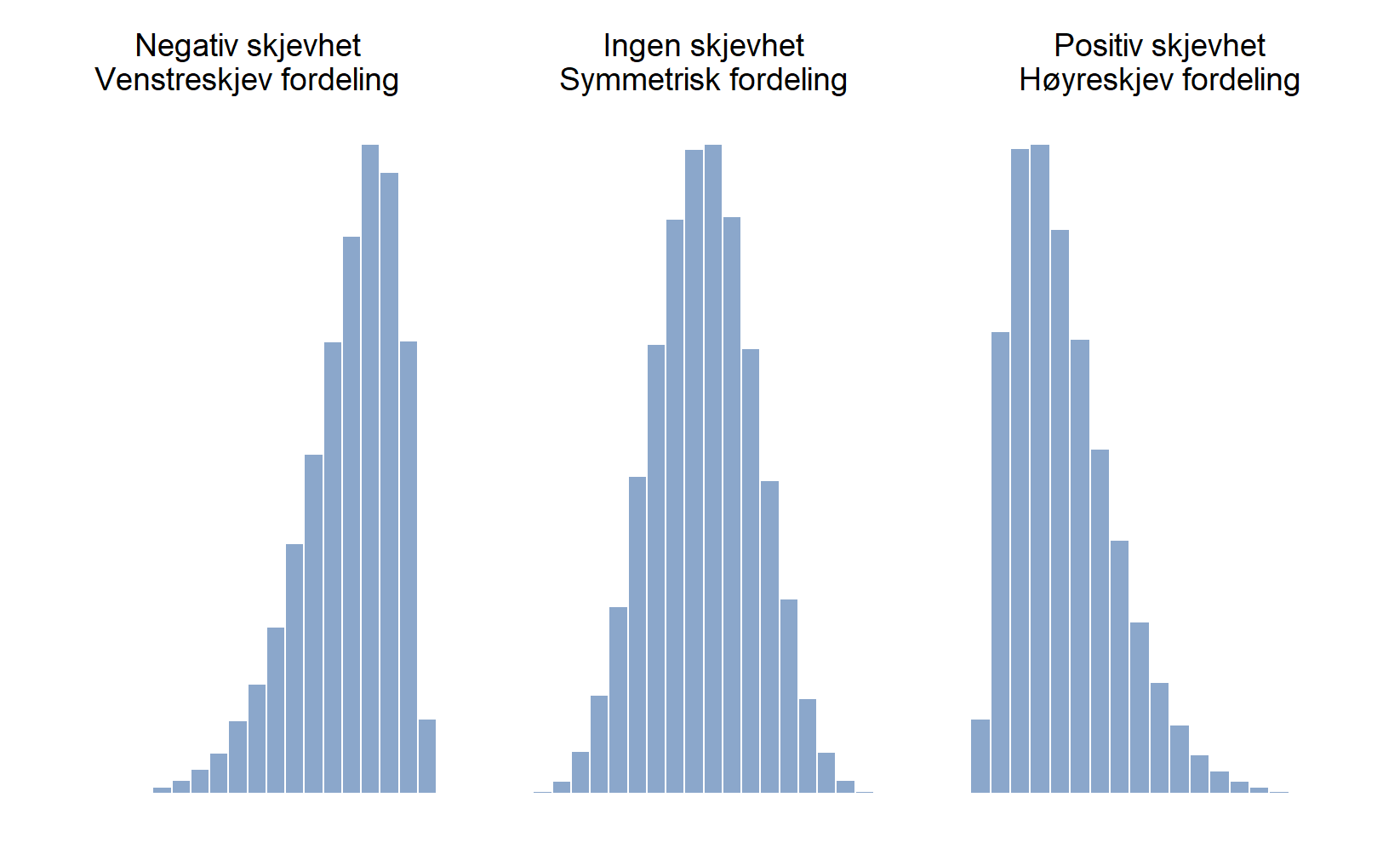
4.6 Deskriptiv statistikk separat for hver gruppe
Det er svært vanlig at du trenger å se på deskriptiv statistikk for forskjellige undergrupper i dataene dine. Det hadde for eksempel vært interessant å vite om de spanske og norske elevene svarer forskjellig på variabelen Likestilling. Eller kanskje om de som ser for seg høyere utdanning svarer forskjellig fra de som seg for seg å stoppe utdanningen etter videregående. Slike spørsmål er svært interessante, og derfor er undergruppeanalyser ofte det masterstudenter benytter til å besvare forskningsspørsmålene sine.
Vi titter på noen rader fra ICCS-dataene våre igjen, se Tabell 4.4.
| Land | Elev-ID | Skole-ID | Trinn | Kjønn | Forventet utdanning | Likestilling | Sosioøkonomisk status |
|---|---|---|---|---|---|---|---|
| Spania | 51180119 | 5118 | 8 | Gutt | Kort utdanning | 42.63710 | 0.17825 |
| Spania | 51210112 | 5121 | 8 | Gutt | Ungdomsskole | 57.13913 | 1.22299 |
| Spania | 51430108 | 5143 | 8 | Jente | VGS | 49.42491 | 0.57663 |
| Spania | 50880122 | 5088 | 8 | Jente | Høyere utdanning | 65.70400 | -0.85618 |
| Norge | 50020111 | 5002 | 9 | Jente | Kort utdanning | 65.70400 | -0.05390 |
Vi ser at de undergruppene vi ønsker å undersøke (Norge/Spania, Høyere utdanning/VGS) er de forskjellige verdiene til nominelle eller ordinale variable (henholdsvis Land og Forventet utdanning). En måte å tenke på verdiene til nominelle og ordinale variable er altså som undergrupper.
Å gjøre deskriptiv statistikk for undergrupper er å gjøre utregningene separat for hver verdi av en nominell variabel.
Dette er ganske enkelt å gjøre i jamovi. For å regne ut deskriptiv statistikk separat for Gutt, Jente og Annet, må jeg dele opp dataene med verdiene i variabelen Kjønn. I jamovi går man nok en gang til menyen for deskriptiv statistikk (“Analyses” → “Exploration” → “Descriptives”). Deretter legger du til variabelen Kjønn i vinduet der det står “Split by”, se den røde markeringen i Figur 4.14.
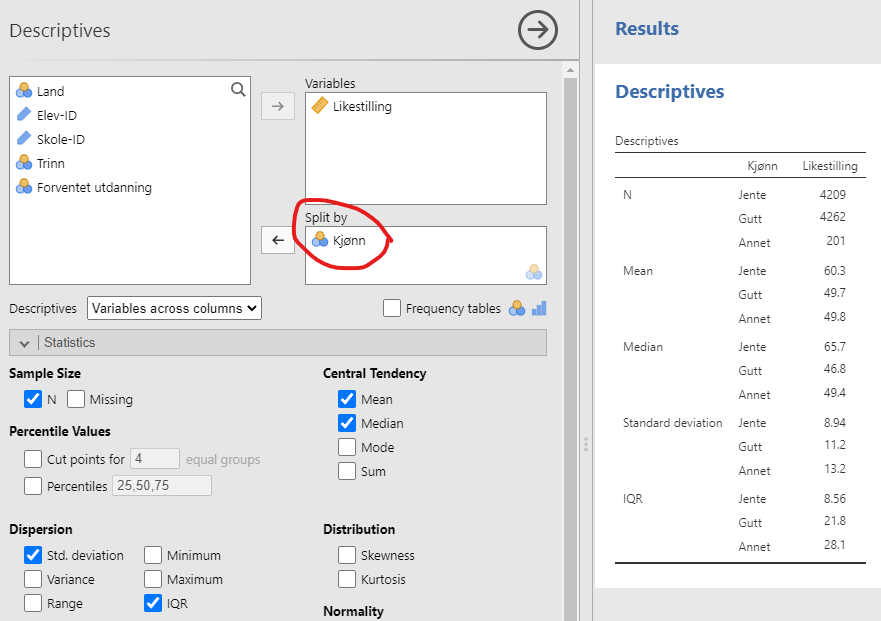
Fra Figur 4.14 ser vi at jentene har mye høyere gjennomsnittskår på Likestilling enn guttene, 60,3 mot 49,7. De som oppga Annet har tilsvarende gjennomsnitt som gutta, 49,8. Jentene har dessuten vesentlig mindre standardavvik, 8,94 mot 11,2. De som oppga “Annet” har mer sprikende svar. Og tolkningen av dataene ser helt lik ut om vi heller ser på medianen og kvartilbredden enn gjennomsnittet og standardavviket.
Vi kan også lure på om det er forskjell mellom Norge og Spania for hvert kjønn. Da legger vi til variabelen Land i “Split by”, se Figur 4.15. Vi ser at de norske jentene er mer for likestilling enn de spanske jentene (61,2 mot 58,8), men at de norske gutta er mindre for likestilling enn de spanske guttene (49,2 mot 50,5)! Skjerpings, gutter!
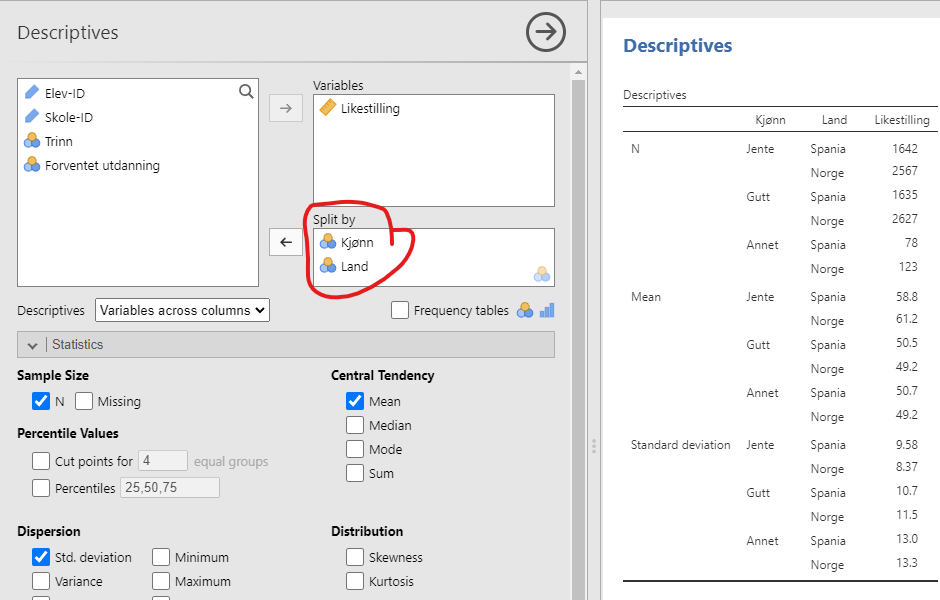
PS: Når man deler inn i ulike undergrupper på denne måten, kan det være at enkelte undergrupper har svært få respondenter. Vi ser i Figur 4.15 at det er svært få som har oppgitt Annet kjønn i Spania, 78 respondenter. Dette er fremdeles mange nok til at det gir mening å regne gjennomsnitt, men andre ganger vil det være like greit å si at man ikke har mange nok respondenter til å gjøre en undergruppeanalyse for akkurat dem. Merk at dette er et etisk problem for forskere, for hvis forskning kan gagne mennesker er det et problem om noen grupper mennesker stadig vekk blir utelatt.
PPS: Merk at krysstabellen, Seksjon 4.1.2, også var en type undergruppeanalyse, bare at den var mellom to kategoriske variable.
4.7 Standardskår
Hittil har alt dreid seg om å beskrive dataene som helhet, men dette delkapittelet dreier seg om å beskrive et enkelt datapunkt i forhold til alle de andre. Dette gjør man ved å regne ut en standardskår for hver person.
Det er ofte nødvendig å regne ut en standardskår fordi måleenheten i seg selv ikke sier så mye. Hvis jeg svarte på spørreskjemaet i ICCS-studien, kunne jeg spurt forskerne “Hvor mye var jeg for likestilling?” og de kunne svart “58”, men svaret ville ikke vært særlig informativt. Det ville vært mye mer informativt hvis de svarte “Du skåret 27% over gjennomsnittet.” Det er akkurat dette en standardskår er.
En standardskår (også kalt en z-skår) er definert til å være antall standardavvik unna gjennomsnittet. Jeg fikk standardskåren z = 0{,}58, mens en mer vanlig norsk gutt i ICCS-studien hadde kanskje fått z = -0,3, som betyr at han svarte 30% av et standardavvik under gjennomsnittet. Man kan regne det ut slik: \text{standardskår} = \frac{\text{opprinnelig skår} - \text{gjennomsnitt}}{\text{standardavvik}}
Man kan tolke denne verdien på ca. samme måte som standardavviket. Hvis du husker tommelfingerregelen om standardavviket (68% av verdiene er innenfor ett standardavvik av gjennomsnittet), så skjønner du at 68% av verdiene er mellom z = -1 og z = 1, 95% av verdiene ligger mellom z = -2 og z = 2 og 99% av verdiene ligger mellom z = -3 og z = 3.
Du har sett standardskår en gang tidligere i kapittelet. I figur Figur 4.12 var det to x-akser, en på bunn og en på topp. x-aksen på bunnen viste de opprinnelige skårene på Likestilling, mens x-aksen på topp viste standardskårene. Dette er det indre blikket jeg har på standardskårer; standardskåren z = 0{,}58 ser jeg for meg som en verdi litt til høyre for gjennomsnittet på et fint normalfordelt histogram.
I tillegg til å la deg tolke en verdi i forhold til resten av dataene dine (som dermed lar deg forstå variabler på skalaer, slik som Likestilling), har standardskårer en annen nyttig funksjon. De kan sammenlignes med hverandre i noen situasjoner der de opprinnelige skårene ikke kan det. Anta for eksempel at vennen min, Bård, svarte på et annet spørreskjema som målte holdning til likestilling mellom kjønnene, og han fikk skår 4. Verdien jeg fikk på ICCS sitt spørreskjema, 58, er overhodet ikke sammenliknbar med verdien han fikk på det andre spørreskjemaet, 4. Men hvis vi vet at Bård sin standardskår var z = 3{,}1 kan vi sammenlikne verdiene. Siden jeg fikk z = 0{,}58 var Bård sin skår mye høyere. Min skår betyr at jeg skårte over gjennomsnittet i min studie, men ikke veldig langt over. Bård sin skår betyr at han svarte himmelhøyt over, han må være likestillingens fanebærer! I hvert fall lå den mange flere standardavvik over gjennomsnittet i hans studie. Hvis utvalget i Bårds studie var medlemmene i “Norsk Forening for Tradisjonelle Kjønnsrolle”, så ville det ikke betydd så mye at han skåret himmelhøytover gjennomsnittet. Derfor er standardskårene kun sammenliknbare hvis utvalgene er det.
4.8 Oppsummering
Å beregne grunnleggende deskriptive statistikk er blant de første tingene du gjør når du analyserer data. Deskriptiv statistikk beskriver utvalget, og har altså ingenting med verdiene for populasjonen.
Vi har dekket disse temaene:
- Mål for sentraltendens: Disse forteller deg hvor dataene dine har sin “kjerne”. De tre mest brukte målene i litteraturen er gjennomsnittet, medianen og typetallet.
- Mål for spredning: Disse viser deg hvor “spredt” dataene dine er. De viktigste målene for å beskrive dataene er variasjonsbredde, kvartilbredde og standardavvik, mens varians spiller en nøkkelrolle i nesten all videre statistikk.
- Skjevhet: Skjevhet måler om variabelen er symmetrisk fordelt, eller har en lang hale til den ene eller andre siden.
- Deskriptiv statistikk for ulike grupper: Er ofte en sentral del av analysen i mastergrader. Vi viste hvordan man gjorde det i jamovi.
- Standardskårer: z-skåren viser hvor mange standardavvik man er over eller under gjennomsnittet. Sørg for at du forstår standardskårer godt, for det er viktig videre i boken.
I neste kapittel kommer den kanskje viktigste delen av deskriptiv statistikk og god dataanalyse – gode visualiseringer!
Bokstaven n, enten den er stor eller liten, beskriver alltid utvalgsstørrelsen.↩︎
Utregningen blir altså å ta “verdien minus gjennomsnittet og droppe fortegnet”. Første verdi på Likestilling er 42,6, så for å regne ut første avvik tar man 42,6 - 54,8 = -12,2, men så dropper man fortegnet og får 12,2.↩︎