| Forventet utdanning | Jente | Gutt | Annet |
|---|---|---|---|
| Ungdomsskole | 407 | 512 | 47 |
| VGS | 787 | 1088 | 36 |
| Kort utdanning | 531 | 836 | 38 |
| Høyere utdanning | 2453 | 1771 | 77 |
9 Analyse av kategoriske data
Nå som vi har dekket den grunnleggende teorien bak hypotesetesting, er det på tide å se på spesifikke tester som brukes ofte i utdanningsforskning. Hvor skal vi begynne? Lærebøker er ikke alltid enige om hva man bør starte med, men jeg velger å starte med kategoriske data og \chi^2-tester, som uttales “kji-kvadrat”, som kanskje er det letteste å forstå.
Husk at begrepet “kategoriske data” er bare et annet navn for “data på nominalnivå” som ble presentert i Seksjon 2.2. I sammenheng med dataanalyse brukes begrepet “kategoriske data” oftere enn “nominalnivådata”. Analyse av kategoriske data refererer til en samling verktøy du kan bruke når dataene dine er på nominalnivå. De brukes også ofte for data på ordinalnivå, men da tar ikke analysen hensyn til at verdiene har en rekkefølge.
9.1 Sammenheng mellom to kategoriske variable: \chi^2-test for uavhengighet
\chi^2-testen tester om det er en sammenheng mellom to kategoriske variable. Den kalles en “test for uavhengighet”, fordi nullhypotesen sier at det ikke er en sammenheng mellom variablene, altså at de er uavhengige av hverandre. Vi benytter oss av dataene fra ICCS-studien som ble presentert i kapittelet om deskriptiv statistikk, Kapitel 4. Vi skal spesielt benytte oss av to variable, Forventet utdanning og Kjønn.
9.1.1 Nullhypotesen og alternativhypotesen
Først må vi uttrykke nullhypotesen for at det ikke er en sammenheng mellom variablene. For at det ikke skulle være noen sammenheng mellom variablene måtte hver verdi av Kjønn (gutt, jente, annet) ha like stor andel som så for seg hver type utdanning (ungdomsskole, VGS, kort utdanning, høyere utdanning).
H_0: Andelen som valgte hver type utdanning er lik mellom kjønnene
H_0 (alternativ måte å uttrykke nullhypotesen på): Forventet utdanning er uavhengig av Kjønn
Hvis man skal uttrykke dette generelt for to variable X_1 og X_2, lyder det:
H_0: Andelen av X_1 sine verdier er lik på tvers av X_2 sine verdier.
Alternativhypotesen blir som alltid bare “alt annet enn H_0:
H_1: Forventet utdanning er ikke uavhengig av Kjønn
For å belyse en \chi^2-test for uavhengighet er det naturlig å først titte på en krysstabell (se Seksjon 4.1.2) med variablene, se Tabell 9.1.
Uffda, det var ikke så lett å se ut fra tabellen om dataene var relatert eller ikke. Det er lettere å lese hvis vi lager tabellen med andeler, for eksempel prosenter, slik som i Tabell 9.2.
| Forventet utdanning | Jente | Gutt | Annet |
|---|---|---|---|
| Ungdomsskole | 9.7% | 12.2% | 23.7% |
| VGS | 18.8% | 25.9% | 18.2% |
| Kort utdanning | 12.7% | 19.9% | 19.2% |
| Høyere utdanning | 58.7% | 42.1% | 38.9% |
Denne tabellen gjør det mye lettere å se om det er en sammenheng mellom variablene, og det ser det kanskje ut til at det er? For eksempel er det mye større andel av jentene som ser for seg å ta høyere utdanning. Spørsmålet som stilles i hypotesetesten er om forskjellene vi ser i tabellen er store nok til å kunne forkaste nullhypotesen om at det ikke er noen sammenheng mellom Kjønn og Forventet utdanning.
9.1.2 Testobservatoren \chi^2 og dens utvalgsfordeling
Nå må vi konstruere en testobservator, altså et tall som vi regner ut på bakgrunn av dataene, som er egnet til å uttale seg om nullhypotesen kan falsifiseres. Idéen bak testobservatoren er at under nullhypotesen har vi en forventning om hvor mange deltagere som skulle vært i hver celle i krysstabellen. Hvis den forventede verdien avviker mye fra den observerte verdien har vi dårlig samsvar med nullhypotesen, så disse avvikene kan brukes til å lage en testobservator. I Tabell 9.3 har jeg vist de forventede verdiene for hver celle i krysstabellen, sammen med de verdiene vi faktisk observerte.
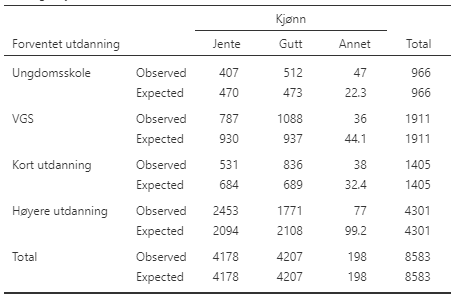
For å regne ut de forventede verdiene gjør man følgende. For ruten øverst til venstre, antall jenter som ser for seg ungdomsskole som høyeste utdanning, regnet jeg først ut hvor stor andel av hele utvalget som ser for seg ungdomsskole som høyeste utdanning. Dette er 966 elever av totalt 8583 elever, som gir at \frac{966}{8583} = 11{,}3\%. Det er 4178 jenter i utvalget og nullhypotesen forventer at jentene har samme andel som ser for seg ungdomsskole som høyeste utdanning, 11,3%, altså 4178\cdot 0{,}113 = 470 jenter.
Avviket mellom den observerte verdien (407) og den forventede verdien (470) blir altså 407 - 470 = -63, som betyr at 63 elever jenter mindre enn forventet så for seg ungdomsskole. Man kunne tenkt at å summere opp disse avvikene ville gitt \chi^2-verdien, men man gå gjøre to ting til. Først må man kvadrere avvikene, akkurat som når man regner ut variansen. Jeg forklarte i kapittelet om varians, Seksjon 4.4, hvorfor man ofte kvadrerte. Deretter må man dele på den forventede verdien. Grunnen til dette er at et avvik på 63 er veldig lite hvis man forventet 1 000 000, men det er ganske masse hvis man forventet 470. Så utregningen for den første cellen blir
\frac{(407-470)^2}{470} = 8{,}44.
Hvis man gjør en slik utregning for hver celle og summerer opp alle resultatene får man testobservatoren \chi^2.
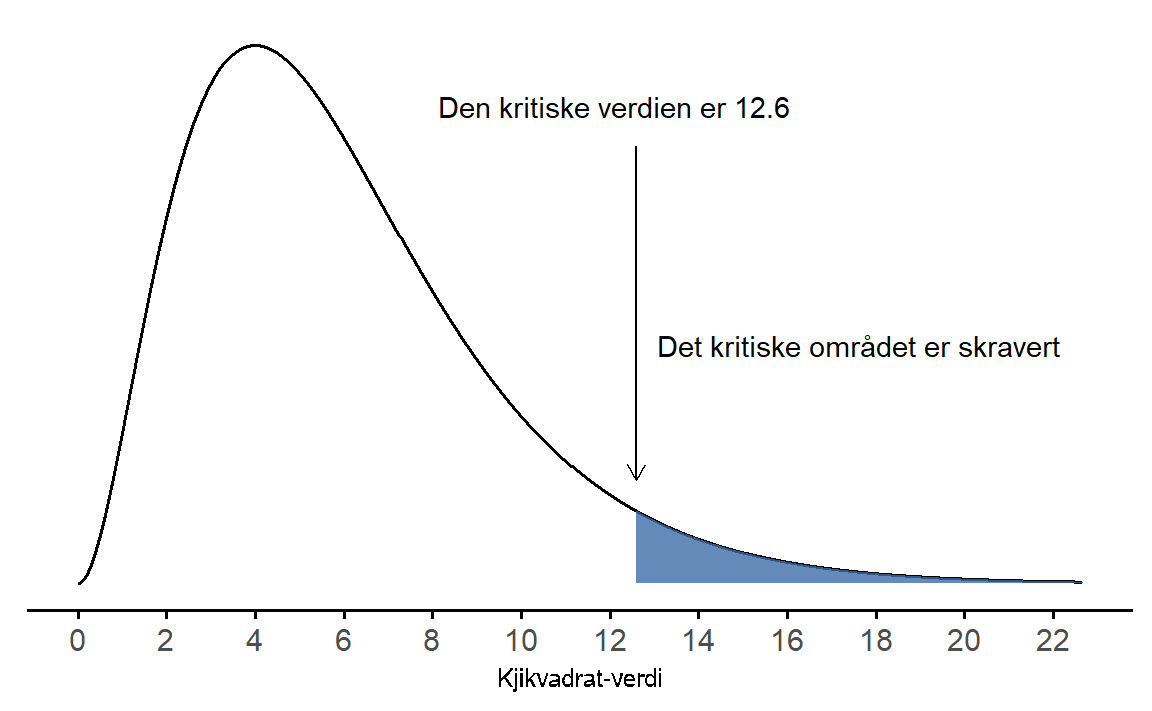
Det som gjør at \chi^2 er egnet som en testobservator er at den måler et avvik fra nullhypotesen og at vi kjenner utvalgsfordelingen, den følger \chi^2-fordelingen som vi viste i Seksjon 6.4.3.
Vi har forenklet litt
Hvis du leser om kjikvadrat-fordelingen et hvilket som helst annet sted vil du se at den finnes i forskjellige versjoner ut fra hvor mange frihetsgrader du har. Vi dropper dette. Programvaren finner det ut for deg, og detaljnivået blir for høyt for denne boka. Intuisjonen bak frihetsgradene er at dess flere celler man har i krysstabellen tilhørende \chi^2-testen, dess usikrere estimat av \chi^2 får man. Siden det er tre verdier av Kjønn og fire verdier av Forventet utdanning har krysstabellen 12 celler. Når utvalgsstørrelsen er 8583 vil det være veldig mange personer i hver celle, som gir et godt estimat. Hvis krystabbelen hadde hatt 500 celler hadde det bare vært noen få personer i hver celle, som ville gitt dårligere estimater. Det er dette frihetsgradene fanger opp.
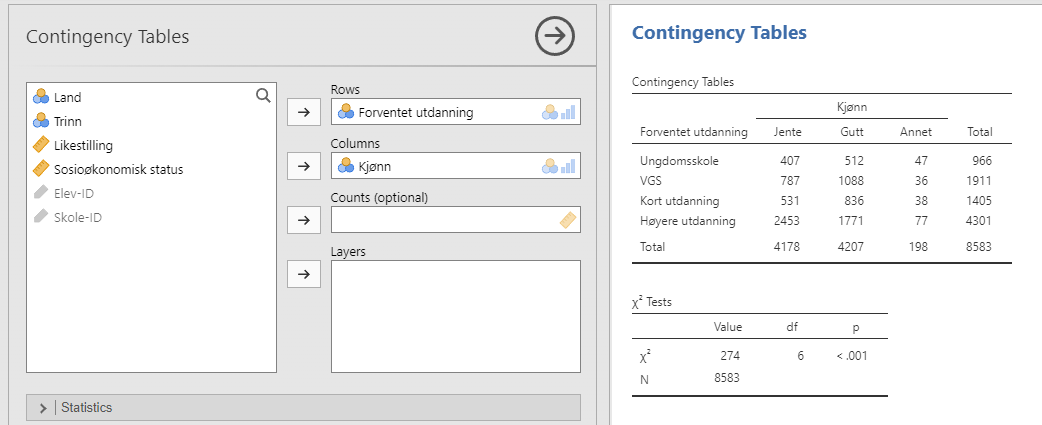
9.1.3 Å gjennomføre testen i jamovi
Nå som vi vet hvordan testen fungerer kan vi se hvordan den utføres i jamovi. Du må trykke på ‘Frequencies’ → ‘Contingency Tables’ → ‘Independent Samples’). Der fyller vi inn Kjønn og Forventet utdanning slik som i Figur 9.2. Resultatene viser en krysstabell og resultatene av \chi^2-testen. Testobservatoren har verdien 274, og hvis vi sammenlikner med Figur 9.1 ser vi at 274 er langt inne i forkastningsområdet. Dette samsvarer med p-verdien som er mege lav, lavere enn 0,001.
Det var enkelt, ikke sant! Du kan også be jamovi om å vise deg de forventede verdiene - bare klikk på avkrysningsboksen for ‘Counts’ – ‘Expected’ i ‘Cells’-alternativene, så vil de forventede verdiene vises i krysstabellen.
Denne utskriften gir oss nok informasjon til å rapportere resultatet:
Testen for uavhengighet viser en signifikant sammenheng mellom hvilke utdanninger kjønnene ser for seg (\chi^2(6) = 274, p< 0{,}001).
Problemet med dette resultatet er at vi ikke aner hvilken vei sammenhengen går. Heldigvis inneholder jamovi en fin måte å visualisere testen på også, se Figur 9.3. Jeg har valgt et stablet stolpediagram der kolonnene er Kjønn.
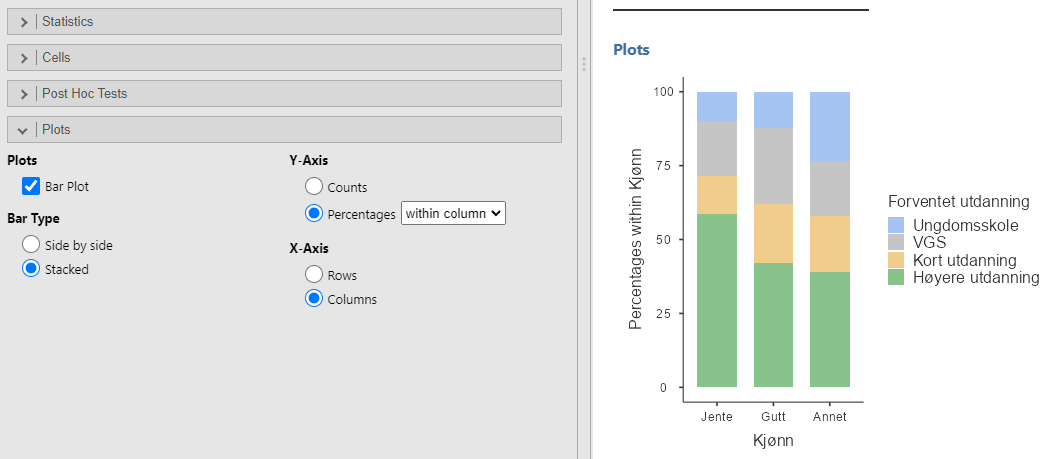
Figuren viser på en flott måte at jentene ser for seg høyere utdanning enn guttene, og at de som har valgt “Annet” ser for seg minst utdanning.
9.2 Sammendrag
Her er det viktigste vi har gått gjennom i dette kapittelet:
- \chi^2-test for uavhengighet brukes for å teste om det er en sammenheng mellom to kategoriske variable. Nullhypotesen er at det ikke er noen sammenheng eller assosiasjon mellom variablene, altså at andelene er like i hele utvalget som i kategoriene til den uavhengige variabelen.
- Testobservatoren \chi^2 måler avviket mellom de observerte verdiene i krysstabellen og de verdiene vi hadde forventet under nullhypotesen.
- Utbroder testresultatene ved å visualisere med et stolpediagram.